I have a couple of one-offs that I use when working with the videos that I’ve taken. I either need to do one thing or another, but I keep coming back to a couple basic actions.
This is my dump of my FFmpeg shorts.
Read MoreRecently I was asked “What did I do that I couldn’t go to Canada”, and before I was able to dialogue the tale I immediately heard “wasn’t it that thing with the felonies?”
The quick answer was “no”, but then I was asked to tell the story about “the felonies.” I still have the email that caused it all…
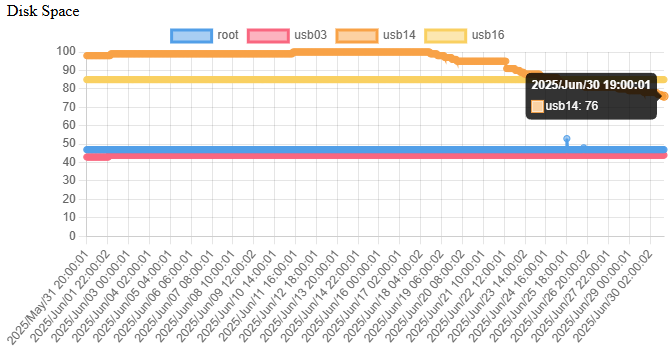
Read MoreAround October of 2021 I was running out of disk space on my 6TB hard drive that I had acquired back on November 2015, so I decided to upgrade to the newest and greatest storage solutions of all time: 14TB of block storage! I went ahead and purchased a WD Elements 14TB USB 3.0 external hard drive, proceeded to format it down and get it ready for storing all my useful content.
From October 2021 to July 2025 I completely filled that volume up, and just recently hit the 100% usage. What to do? By the looks of the graph I figured that out without having to delete any files…
A minor adventure, yet one worth documenting. I’ve been wanting to get MariaDB updated on my VPS for the longest of time but do it in a way with precompiled binaries so I have some control over what I run and, if needed, some flexibility with versions without having to dnf/yum/apt-get things in and out.
To note I tested this on my test machine running 4.18.0-348 and it wasn’t quite happy with getting 11.8.2 rolled out onto it. I realized that the home test machine is a bit old so I had to defer to 10.11.13. Once that was all done I fired up a virtual Rocky9 host running 5.14.0-* and, with the same instructions with the test machine successfully got 11.8.2 slammed on that with no data loss.
Another “Today I Learned”, except I was more “doing” than learning. Back in 2024 I was happy to find that the camera I invested in to monitor my kids doing homework back in the COVID days supported RTSP. I made a note to see if I can take it a bit farther, and if it wasn’t for the fact that the DCS-8526LH was eating Micro-SD cards and I was losing valuable information I wouldn’t be where I’m at now.
Enter the “Home DVR”…
Read More